

이번 포스팅에서는 본 프로젝트의 두번째 주제인 데이터웨어하우스 테이블 구조 최적화와 두 분석의 결과를 실제 적용하여 검증한 내용을 소개하겠습니다.
3. 데이터웨어하우스 테이블 구조 최적화
a. 쿼리문 파싱
먼저 사용자들이 어떤 테이블을 조회하는지 파악하기 위해 쿼리 이력 로그에 나오는 SQL 쿼리문을 파싱하는 작업부터 시작했습니다. Python에는 sqlparse(https://pypi.org/project/sqlparse/>)라는 쿼리문 파싱 모듈이 있습니다. 해당 모듈은 쿼리문을 토큰 형식으로 분해해서 변환해 줍니다. 이 모듈을 이용해서 쿼리문의 구조를 정형화된 테이블로 변환하는 로직을 만들었습니다. (<그림 1> 참조)
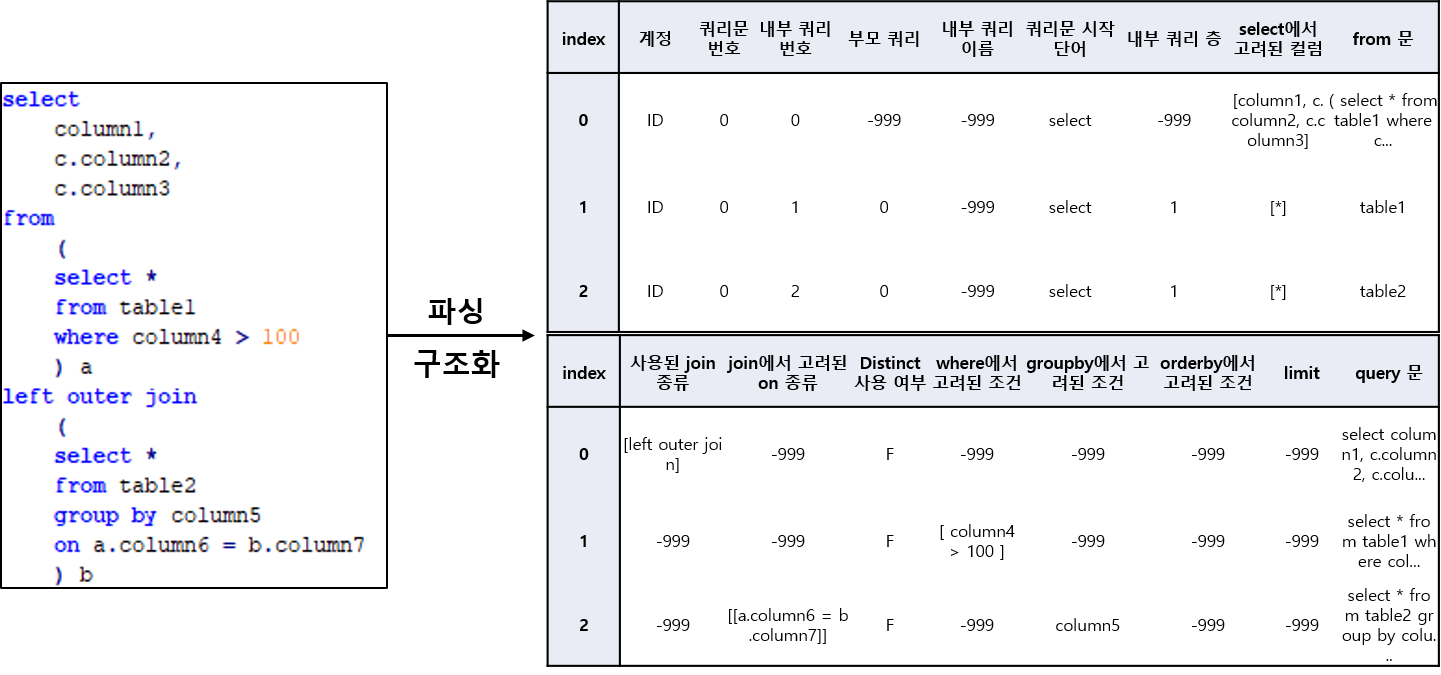
<그림 1> 쿼리문 파싱 테이블 생성 예시
b. 개선 대상 테이블 찾기
앞서 설명했듯이 데이터웨어하우스는 같이 집계할 정보들이 하나의 테이블에 모여 있는 것이 좋습니다. 즉, 하이브 사용자들의 쿼리 이력을 분석했을 때 A라는 테이블과 B라는 테이블이 같이 사용되는 빈도가 높다면 이 두 테이블을 하나로 병합하여 제공하는 것이 좋을 것입니다. 하지만 만약 A 테이블이 단독으로도 많이 사용되거나 혹은 C, D, E 등의 다른 테이블과도 자주 같이 사용되는 테이블이라면, A와 B를 병합하는 것이 좋은 선택이 아닐 수 있습니다. 결국 이런 전반적인 테이블 간의 조회 관계를 감안하여 적절한 병합 대상을 찾는 것이 필요했습니다.
이를 위해 먼저 최근 1년 동안 실행된 쿼리문에서 사용된 테이블 목록을 추출했습니다. 이 중에서 개인이 생성한 테이블이나 혹은 원천 데이터를 1:1로 매핑한 테이블은 제외하고 ETL 작업을 통해 생성된 테이블만 추렸습니다. 이후 분석 대상 테이블의 모든 쌍에 대해서 한 쿼리에서 두 테이블이 같이 사용된 ‘공통사용비율’을 아래와 같은 수식을 이용해 구했습니다.
이 공통사용비율이 1에 가깝다는 것은 두 테이블이 거의 항상 같은 쿼리에서 사용된다는 것을 의미하는 것이고 0에 가깝다는 것은 각자 독자적으로 사용되는 경우가 더 많다는 것을 의미합니다.
<그림 2>을 보면 대부분의 테이블 쌍이 낮은 값을 갖지만 일부 테이블 쌍은 0.8 이상의 높은 값을 갖는 것을 알 수 있습니다. 다시 말해 이런 테이블 쌍은 전체 쿼리 중 80% 이상에서 같이 조회된 것이므로 하나의 테이블로 병합하는 것이 더 효율적일 수 있는 것이죠.
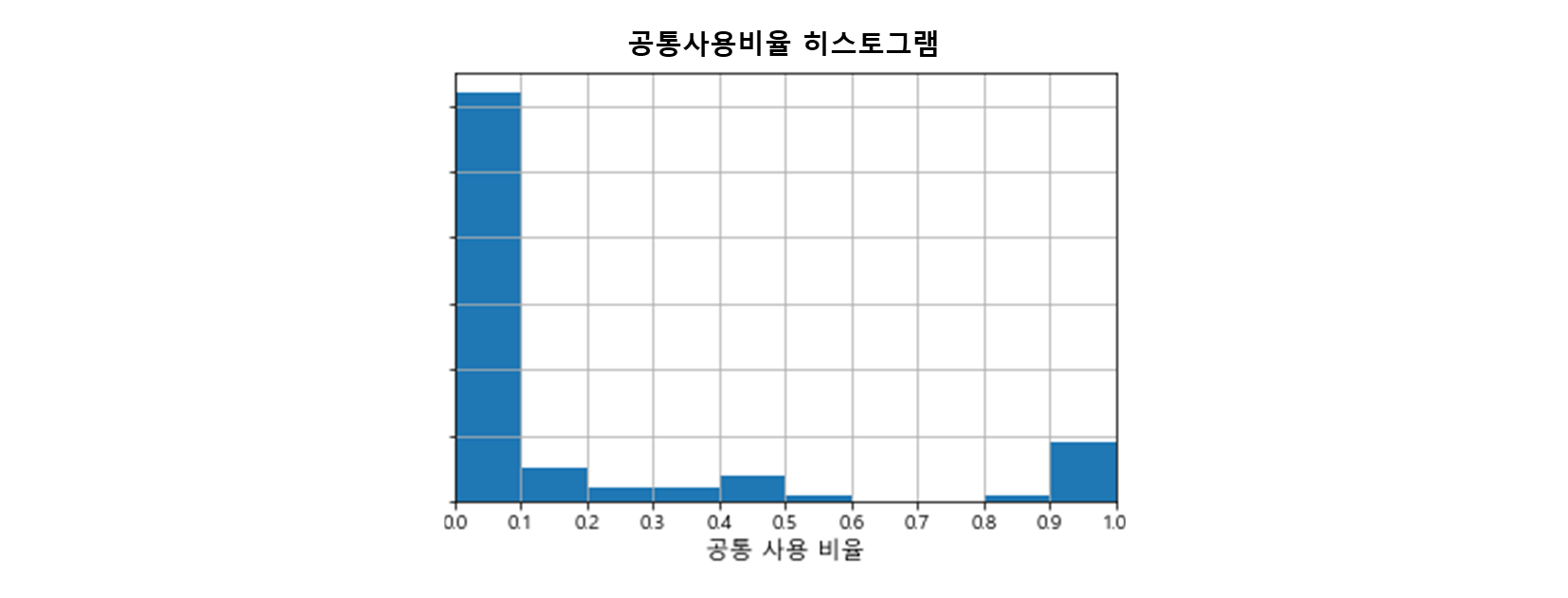 <그림 2> 분석 대상 테이블 쌍의 공통사용비율 분포
<그림 2> 분석 대상 테이블 쌍의 공통사용비율 분포
그런데 병합 대상이 꼭 두 개의 쌍으로만 이뤄질 필요는 없을 것입니다. 3개 혹은 그 이상의 테이블들이 항상 같이 사용된다면 이들 역시 하나의 테이블로 묶는 것이 좋겠죠. 그래서 이런 경우도 모두 고려하기 위해 저희는 각 테이블을 노드로 하고 이 공통 사용 비율을 가중치 엣지로 갖는 네트워크 그래프를 만든 후 노드들이 서로 긴밀하게 연결되는 ‘클리크 (clique)’를 추출하는 방법을 사용했습니다 (네트워크 분석 기법에 대한 자세한 내용은 ‘네트워크 분석기법을 활용한 게임 데이터 분석’을 참고하세요). <그림 3>은 이렇게 해서 생성한 테이블 간의 관계 네트워크를 시각화한 자료입니다.
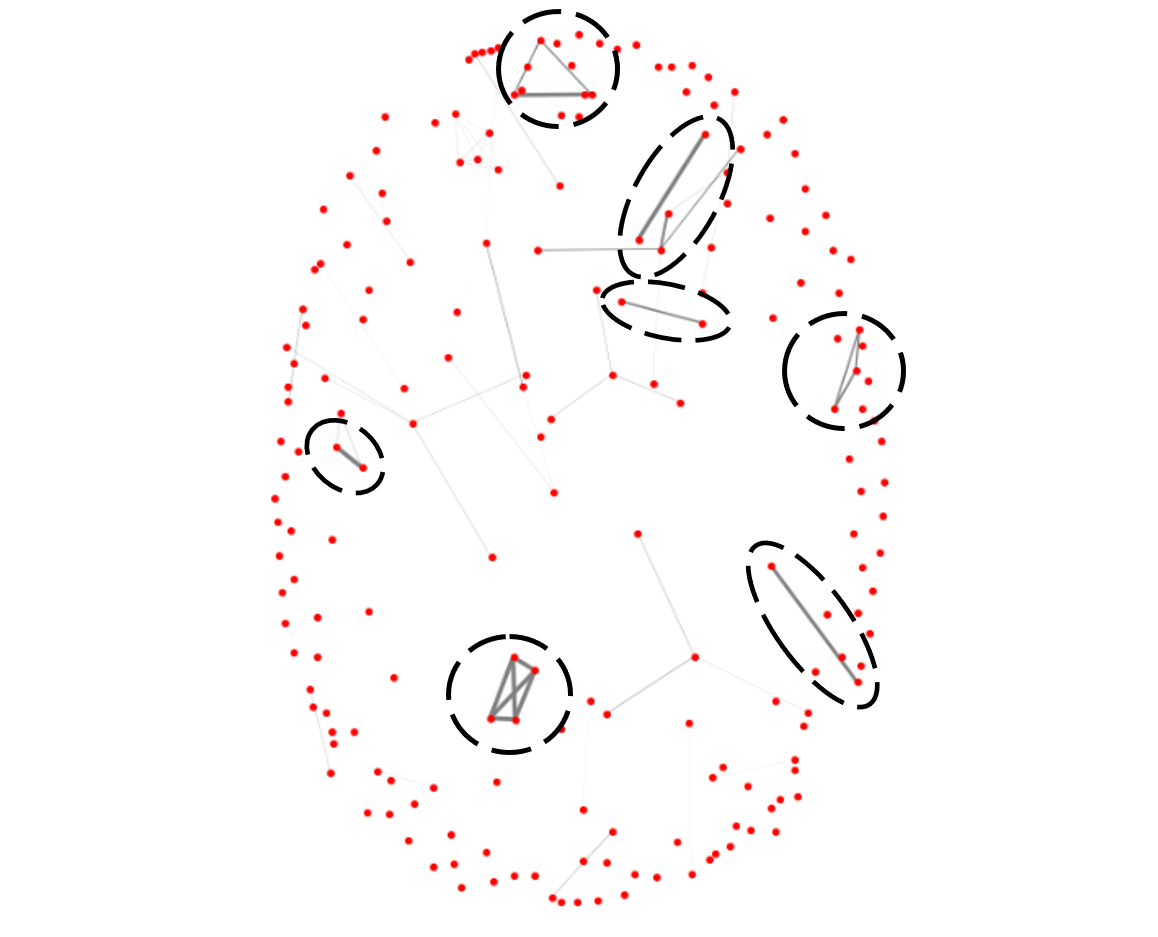 <그림 3> 테이블 공통 사용 비율 네트워크(테이블 = 붉은 점, 회색 연결선 = 공통 사용 비율, 눈에 띄는 테이블 공용 클러스터 파선 동그라미 표시)
<그림 3> 테이블 공통 사용 비율 네트워크(테이블 = 붉은 점, 회색 연결선 = 공통 사용 비율, 눈에 띄는 테이블 공용 클러스터 파선 동그라미 표시)
<그림 3>에서 볼 수 있듯이 다른 테이블과는 분절된 채 자기들끼리 연결된 7개의 클러스터(파선동그라미)를 확인할 수 있었습니다. 이 7개의 클러스터를 병합 대상 테이블 후보 그룹으로 놓고, 쿼리문 파싱 데이터를 통해 실제 병합에 타당한 대상인지 추가 검토 작업을 했습니다. 예를 들어 실제 쿼리문을 봤을 때 맥락 상 병합에 적절하지 않은 경우이거나 혹은 높은 공통 사용 비율을 가지지만 총 사용 횟수가 높지 않아 병합으로 인한 개선 효과가 크지 않을 수 있기 때문이죠. 이런 추가 검토 과정을 거친 후 최종적으로 3개의 그룹을 병합 대상으로 추출했습니다. 솔직히 분석하는 입장에서는 기대보다 최종적으로 추출된 테이블의 수가 많지 않아 다소 아쉬웠지만 반대로 생각해 보면 현재 구축되어 있는 데이터웨어하우스의 구조가 그 만큼 잘 설계되어 있다는 것을 의미하는 것이겠죠. ^^;
4. 개선 효과 검증하기
앞서 소개한 두 가지 분석에 대한 실제 개선 효과를 검증해 보기 위해 아래와 같은 작업을 진행해 보았습니다.
a. capacity scheduler 최적화 검증
먼저 capacity scheduler의 자원 할당 정책 최적화 결과의 효용성을 검증해 보기 위해 하둡 클러스터 운영을 담당하는 부서의 협조를 받아 일정 기간 동안 실제로 설정을 변경해보고 적용 이전과 이후의 각 데이터 처리 작업에 걸린 소요 시간의 변화를 살펴보았습니다. 만약 최적화가 의도대로 잘 되었다면 큐별로 요청되는 작업량에 맞게 시스템 자원이 잘 배분될 것이고 그렇다면 특정 큐의 병목 현상이 완화되어 작업 대기 시간이 전에 비해 줄어들 것이라 기대했죠.
그러나 검증 작업은 예상보다 쉽지 않았습니다. 먼저 현재 시스템에 쌓이는 로그에서는 실제 작업이 수행된 시간과 대기 시간을 구분하기가 어려웠습니다. 단지 요청이 들어온 시작 시간과 작업이 종료된 시간만 알 수 있었죠. 또한 정책 변경 전/후에 하둡 시스템에서 수행된 작업이 완전히 같지는 않기 때문에 정확한 비교를 하기가 어려웠습니다. 게다가 저희가 검증 테스트를 했던 시기는 신규 게임이 론칭하기 직전이었는데 당시에 론칭 준비를 위한 여러 가지 사전 분석이나 보고서 작성이 많아서 쿼리량이 평소 대비 다소 증가했다고 하더군요…
어쨌든 이런 여러 가지 한계점에도 불구하고 검증을 진행했고 결과는 아래 <표 1>과 <표 2>를 통해 알 수 있습니다. <표 1>은 기존에 운영되고 있던 할당 정책에서 신규 정책으로 변경되면서 증감된 리소스 할당량(%)을 나타냅니다. 시스템 사용량 분석을 통해 할당량이 어떻게 조정되었는지 알 수 있습니다. <표 2>는 이렇게 조정된 신규 정책의 적용 전후 소요 시간의 변화를 시간에 따라 큐별로 비교한 결과입니다. 여기서 유의성 검증은 데이터가 정규분포를 만족하지 않았으므로 Mann-Whitney-U-test를 사용했습니다.
 <표 1> 할당 정책 변경 이후 리소스 할당 증감량(%p)(증가 = 붉은 배경, 감소 = 파란 배경)
<표 1> 할당 정책 변경 이후 리소스 할당 증감량(%p)(증가 = 붉은 배경, 감소 = 파란 배경)
 <표 2> Duration의 전후 기간 비교 결과(유의미한 증가 = 붉은 배경, 감소 = 파란 배경, 차이 없음 = 흰 배경, 전후 기간 모수 각 10개 미만 = 회색 배경)
<표 2> Duration의 전후 기간 비교 결과(유의미한 증가 = 붉은 배경, 감소 = 파란 배경, 차이 없음 = 흰 배경, 전후 기간 모수 각 10개 미만 = 회색 배경)
가장 먼저, <표 1>과 <표 2>의 비교를 통해 할당량 증감과 Duration의 증감의 패턴이 일치하지 않는다는 것을 알 수 있었고 소요 시간 증가한 시간대가 다수 존재하는 것을 알 수 있습니다.
Queue A는 전반적으로 자원 할당량이 증가했는데, 오전과 오후 일부 시간대에서 소요 시간이 감소하긴 했으나 새벽과 나머지 오후 시간대에서 소요 시간이 증가한 것을 알 수 있었습니다. Queue B는 전반적으로 자원 할당비율을 줄였기 때문인지 가장 많은 시간대에서 소요 시간 증가 현상이 관찰되었습니다. 한편 Queue C 는 오후 시간대에 자원 할당 비율을 늘렸으나 소요 시간에는 큰 변화가 없는 것으로 측정되었습니다. 마지막으로 Queue D 의 경우 새벽 시간대에 자원 할당량을 줄였으나 소요 시간의 변화가 없었고 할당량을 늘린 오전 시간대에 실제 소요 시간이 감소한 것을 알 수 있었습니다. 대신 아무런 변동이 없었던 저녁 시간대에 소요 시간이 증가했죠. 종합하자면, 시스템 자원 할당 비율의 변화와 소요 시간의 변화 사이에 특별한 상관성을 찾기 어려웠습니다. (ㅠㅠ).
하지만 다행히 클러스터 운영 부서에서는 효과 검증이 어려운 상황에 대해 충분히 이해하시는 한편 저희가 분석을 위해 사용한 기법에 대해서 높이 평가해 주셨습니다. 또한 이후 저희가 제안한 ‘자원 사용 효율’ 지표를 활용하여 스케줄러 정책을 최적화해 나가겠다는 피드백을 받았습니다.
b. 테이블 병합 효과 검증
두번째 분석이었던 테이블 구조 변경 시 기대 효과에 대한 검증은 실제 도출된 3개의 테이블 그룹에 대한 실제 사용자들의 쿼리를 이용해서 1) 원래 쿼리를 그대로 실행한 경우와 2) 병합 테이블이 제공될 경우 수정된 쿼리를 사용하는 경우에 대해서 다양한 시간대와 요일에서 여러 차례 반복 실행해 본 후 duration의 차이를 분석했습니다.
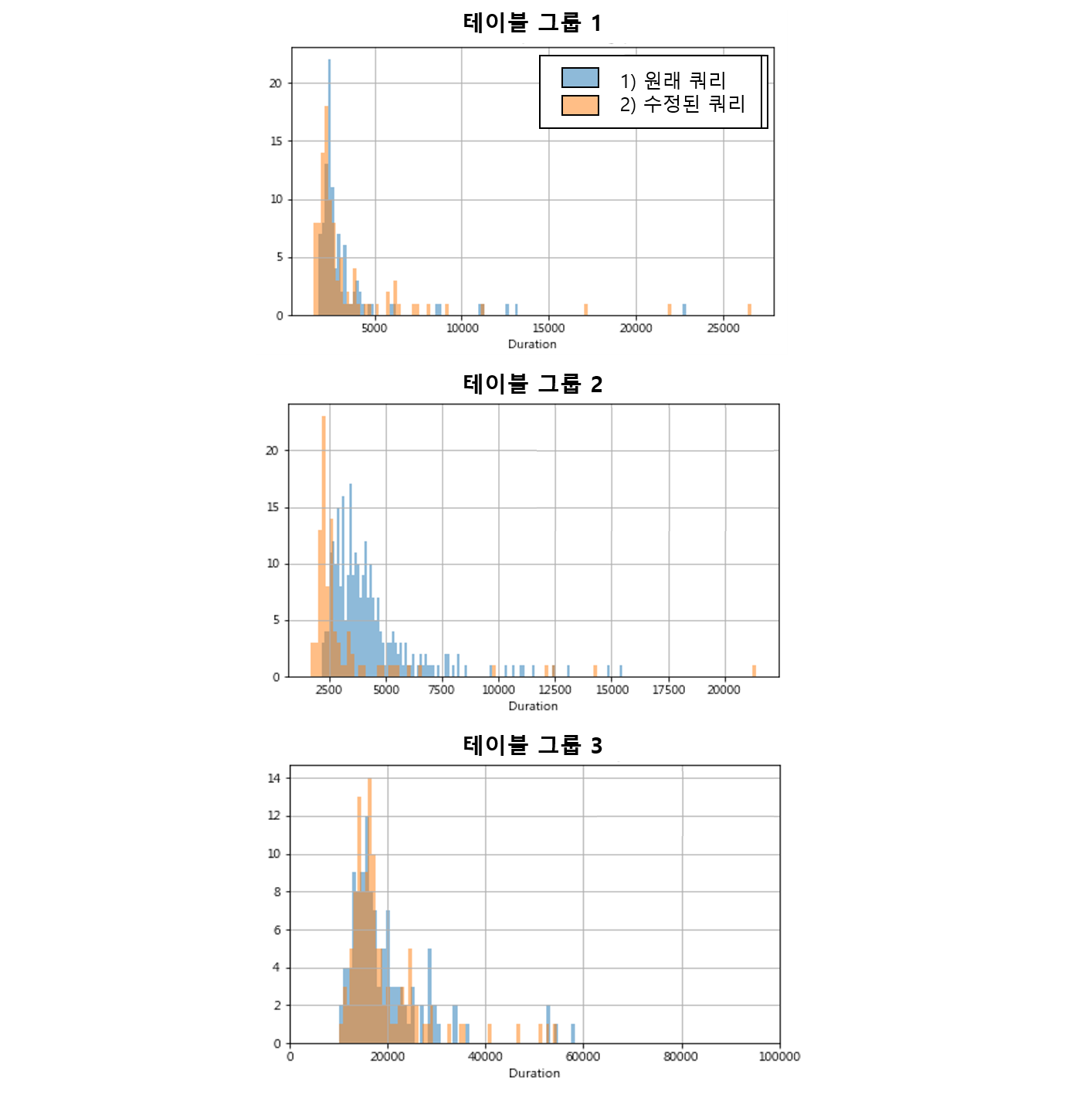 <그림 4> 세 가지 테이블 그룹의 1) 원래 쿼리와 2) 수정된 쿼리의 duration 분포
<그림 4> 세 가지 테이블 그룹의 1) 원래 쿼리와 2) 수정된 쿼리의 duration 분포
병합 대상이었던 세 개 그룹 중 하나의 그룹(그림 4의 테이블 그룹2)에서 통계적으로 유의미한 개선 효과가 있는 것으로 나타났는데 중간값 기준으로 약 37% 정도의 duration단축 효과가 있었습니다. 다만 해당 그룹은 작업 소요 시간이 그리 오래 걸리지 않는 비교적 작은 규모의 쿼리 작업이라는 점과 병합된 테이블의 사이즈가 대상 테이블 사이즈의 총합보다 커서 저장 공간의 효율성 관점에서 단점이 있어 실제 적용에 적절하지 않다는 결론을 얻었습니다. 그리하여 종합적으로 실적용에 적절한 케이스가 아쉽게도 없는 것으로 결론지었습니다.(ㅠㅠ)
5. 분석 후기
본 분석은 저의 입사 이후 분석 목표 설정부터 효과 검증까지 전체 과정을 단독으로 진행해 본 첫 프로젝트였습니다.
사실 하둡이나 하이브에 대한 배경 지식이 부족한 상태에서 낯선 용어나 시스템 로그 데이터의 특징을 익히는데 시간이 오래 걸리는 바람에 초기에 날려버린 시간이 많았고 그래서 장기간 노력한 것에 비해 썩 만족스러운 결과를 얻지 못한 것에 아쉬움이 남습니다. 일부 쿼리의 사용량 정보 누락 이슈와 분석에 사용된 집계 정보가 실제 리소스 사용량을 대변하기에 한계가 있다는 이슈 등, 분석 과정에서의 아쉬운 부분들도 많습니다.
하지만 저 나름 헤매는 과정에서 사내 시스템의 관리 현황을 파악할 수 있었고 타 부서 담당자분들과의 커뮤니케이션 방식을 경험했습니다. 그리고 도움을 요청하는 적극성이 얼마나 중요한지에 대해 배웠기에 큰 보람을 느낍니다.
프로젝트 진행 과정에서 빛을 보지 못한 아이디어들이 많았습니다. 쿼리문 분석을 통한 사용자 맞춤 쿼리문 작성 팁 제공 서비스, 쿼리문 작업 예상 시간 알림 서비스, 그 외에도 각종 사내 이벤트 이해를 통한 사용량 예측 등 다양한 가능성을 시도해보고 싶었습니다. 테이블 병합 이력 분석도 일부 테이블에 대하여 분석한 후, 모든 테이블에 대해 시도한 후에 테이블 사용 이력으로 구조의 효율화에 도움되고 싶었습니다. 과거 다양한 아이디어를 되돌아 보건데 향후 좋은 기반이 마련되었을 때 다시 한번 시도해보기에 좋은 분석이라 생각합니다.
본 분석이 향후 이와 비슷한 시스템 최적화 관련 분석에서 참고될 만한 초석같은 분석이 되길 바라며, 여러 시행착오를 겪을 기회를 주신 것과 진행 과정에서 도움 주신 많은 분들께 감사드립니다.