
주의 사항
변환을 이용하면 비선형적인 함수 관계를 선형으로 바꿔 다룰 수 있다. 그 대신 계수 해석에서는 몹시 조심해야 한다. 우선, %로 간편하게 근사치로 해석을 하려면 각 변화량이 크면 안된다. 근사치의 오차가 너무 큰 상황에서 근사치를 쓰면 안되는 것이다. 특히 주의해야 할 것이 더미변수다. 만일 설명 변수에 더미 변수가 들어 있고, 종속 변수가 로그 변환되어 있다면, 계수 값을 그대로 log-level 모델에 따라서 로 해석하면 곤란하다. 더미 변수는 질적 변수이고, 변수의 차이는 측정할 수 없다. 이 경우는 을 변화율로 따져야 한다.
사례
log-level 모형에서 더미 변수 해석

이 회귀분석은 분석 대상이 된 표본 학생들의 쓰기 점수를 성별, 읽기 점수 그리고 수학 점수로 회귀한 결과이다. female 계수(1이면 여성, 0이면 남성)는 어떻게 해석해야 할까? 앞서 보았듯 더미 변수는 질적인 변수다. 따라서 계수에 100을 곱해 여자 성별이 11.4% 더 높은 점수를 준다고 해석해서는 곤란하다. 의 결과에 따라서 약 12% 정도 더 높은 점수를 준다고 보는 것이 맞다. 다른 계수들은 어떨까? 다른 변수은 모두 연속 함수이고 계수 값들이 크지 않음을 알 수 있다. 따라서 근사 값로 해석하는 것이 가능하다. 즉, 읽기 점수가 1% 증가하면 글쓰기 점수는 약 0.66% 정도 증가한다.
level-log 모형에서 변수 해석

의 계수는 어떻게 해석해야 할까? read 값은 연속 값이므로 1%의 작은 값을 취하는 것이 가능하다. 따라서 근사 값으로 해석해도 무방하다. 앞서 보았 듯 read 값의 1% 증가는 만큼의 효과를 종속 변수에 준다. 종속 변수는 level이라는 점을 확인해두자. 즉,read 값이 1% 증가하면 쓰기 점수가 약 0.17 만큼의 증가한다.
log-log 모형에서 변수 해석
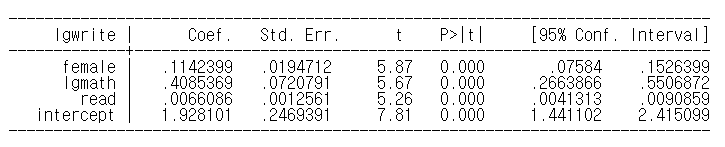
는 어떻게 해석해야 할까? 근사 값로 해석하면 된다. 수학 점수 1% 상승은 쓰기 점수 0.4% 상승을 가져온다.
(부록) log-log 계산
양변에 로그를 취하면,
만일 , 가 충분히 작다면,
