

우리 지금 잘하고 있는 거 맞지?
어느 기업이든 회사의 서비스나 상품에 대한 판매 전략을 세우고 매출을 올리기 위한 다양한 마케팅 이벤트나 프로모션을 하고 있을 것이다. 이 때 진행 중인 이벤트나 프로모션이 실제로 얼마나 효과가 있는지 파악하는 것은 중요한 문제이다. 그런데 그 효과는 어떻게 측정할 수 있을까?
가장 직접적인 방법은 실험을 하는 것이다. 임의로 집단을 둘로 나눈 후, 한쪽에는 프로모션을 진행하고 다른 한쪽에는 프로모션을 진행하지 않는 것이다. 만약 두 집단 사이에 매출에 차이가 있다면 이것을 프로모션 효과라고 할 수 있다. 이런 방법을 ‘A/B 테스트‘라고 한다. A/B 테스트는 효과를 직접적으로 측정할 수 있는 장점이 있지만, 실제 적용하려면 여러 가지 제약이 있다. 한 예로, 어떤 프로모션을 진행하는데 한 쪽은 더 좋은 보상을 주고, 다른 한 쪽은 덜 좋은 보상을 주는 식으로 차등 실험을 하면 형평성에도 어긋날 뿐 아니라 자칫 고객의 반발을 살 수 있다. 심지어 고객끼리 서로 다른 보상을 받았다는 사실을 인지하게 되면, 편향된 결과를 얻을 수도 있다.
때문에 마케팅 부서에서는 주로 프로모션을 진행한 시기 전후의 매출이나 유저 유입량을 비교하는 방법을 많이 사용한다. 그러나 이 방법 역시 문제가 있다. 가령, 게임 서비스에서 고객의 게임 접속을 독려하기 위해, 오늘부터 접속하면 특정 아이템을 주는 출석 보상 이벤트를 시작했다고 하자. 이 이벤트를 시작하기 전인 어제는 10명의 고객이 접속했는데 오늘은 70명이 접속했다면 이벤트 효과로 60명이 더 접속한 것이라고 볼 수 있을까?
얼핏 그렇게 생각하기 쉽지만 실제로는 여러 가지 변수를 고려해야 한다.
첫째, 주기성을 고려해야 한다. 만약 해당 게임이 일반적으로 평일보다 주말에 접속하는 사람이 더 많은데, 마침 이벤트 전날이 금요일이었다면 어떨까? 접속량이 늘어난 것이 이벤트 효과인지 주말 효과인지 구분하기는 쉽지 않을 것이다. 따라서 이런 경우에는 전날과 비교하기 보다는 지난 주 토요일과 비교하는 것이 더 합당할 것이다. 그래서 보통 지표를 비교할 때는 이런 주기성을 고려하여 전날 뿐 아니라 전주, 전월, 전분기 대비 증감 정도를 확인한다. 하지만 이것 역시 정확하지 않을 수 있다. 만약 지난 주가 연휴였다면? 혹은 다른 프로모션을 진행 중이었다면? 지난 달이 방학이었다면? 결국 이런 주기성을 고려하더라도 상황은 점점 더 복잡해진다.
둘째, 프로모션이 한 시점에 하나만 진행되지 않을 수 있다. 대개의 경우, 많은 업체에서는 여러 이벤트나 프로모션을 동시에 진행한다. 즉, 이벤트 시작 후 늘어난 접속 인원 70명은 온전히 출석 보상 이벤트만으로 발생한 결과라고 보기 어렵다.
셋째, 외부적인 요인이 있을 수 있다. 고객 사이에서 게임이 재미있다고 입소문을 타기 시작하면서 갑자기 접속 인원이 크게 늘어났을 수도 있고 경쟁 업체의 게임이 출시되거나 혹은 기타 여러 가지 외부 사건이 영향을 줄 수 있다. 물론 이러한 외부 요인으로 인한 영향까지 우리가 모두 알 수는 없다. 하지만 원래 접속량이 어떤 패턴으로 상승 또는 하락했는지, 특정 요인으로 인해 크게 증감하는 경우는 없었는지 등을 발견하는 것은 지표 분석 시 중요한 작업이다.

[그림1] 단순히 숫자만 보고 판단하기에는 너무 많은 변수들이 존재한다.
지표에 영향을 주는 것들이 이렇게나 많습니다.
결국 단순히 프로모션 전후의 지표를 비교하는 것 역시 프로모션의 효과를 추정하기에는 적절한 방법이 아니다. 프로모션의 효과를 정확히 추정하려면, 효과를 측정할 때 사용하는 지표에 영향을 주는 여러 가지 요인들을 먼저 고려해야 한다. 일반적으로 프로모션 외에 지표에 영향을 줄 수 있는 요인은 다음과 같다.
트렌드: 게임 지표는 일반적으로 장기간에 걸쳐 서서히 감소하는 추세를 보이는 경우가 많다. 출시한 지 얼마되지 않았을 때 매출 수준과 출시한 지 5년이 지난 뒤 매출 수준은 차이가 있기 마련이다.
주기성: 주, 월, 계절 등에 따른 주기적인 패턴이 존재할 수 있다. 예를 들면 평일과 주말의 접속 유저 수 비교가 있다. 과거 일별 접속 유저 수를 시계열 그래프로 그려봤을 때, 주말에는 크게 증가하고 평일에는 크게 감소하는 패턴이 보인다면, 접속 유저 수라는 지표에 영향을 주는 요인으로 주말 혹은 평일 여부라는 항목을 둘 수 있다. 또한 일주일 단위로 업데이트를 진행하는 게임의 경우, 해당 업데이트 날짜(예: 수요일) 매출이 증가하기도 한다.
구조 변화: ‘트렌드’가 일별 지표 시계열의 장기적인 증감 추세를 의미한다면, ‘구조변화’는 이보다 더 급격한 수준 변화를 말한다. 경쟁사 게임 출시, 같은 IP에 속하는 다른 게임의 출시 등으로 기본 매출 수준(베이스라인)이 갑자기 변동할 수 있다.
기타 이벤트 효과: 프로모션 외에도 지표에 영향을 주는 여러 가지 이벤트가 있을 수 있다. 가령, 휴일의 경우 평일에 비해 지표가 증가 혹은 감소할 수 있다. 또한 게임 서비스의 경우 대개 월초에 매출이 크게 증가한다. 이른바 ‘월초 효과’라 부르는데 매월 1일마다 게임 회사에서 정해놓은 아이템 구매 한도나 카드 결제, 모바일 소액 결제 한도가 초기화되기 때문에 생기는 현상이다.
정리하자면, 프로모션 효과를 제대로 추정하려면, 위에 기술한 여러 가지 요인이 미치는 영향력을 ‘통제한 상태’, 즉 ‘다른 조건이 동일한 경우’ 프로모션이 진행된 시점과 아닌 시점의 지표를 비교해야 한다. 그러나 현실적으로 이런 조건에 맞는 데이터를 찾기는 쉽지 않다. 다행히 방법이 없는 것은 아니다. ‘회귀 분석’은 바로 이러한 문제를 해결할 때 사용할 수 있는 가장 보편적이고 강력한 도구이다.
그런데 올바른 회귀 모델을 만드는 것이 그리 만만한 작업은 아니다. 특히 이 경우 시계열 회귀 분석이 필요한데 이것은 회귀 분석 중에서도 어려운 분야에 속한다. ARIMA 와 같은 잘 알려진 기법들이 있지만 지나치게 일반적인 방법이기 때문에 목적에 맞게 사용하기 다소 까다롭다.
그래서 구글이나 페이스북이 이런 걸 만들었습니다.
그래서 좀 더 목적에 맞게 특화된 시계열 지표 분석용 라이브러리들이 있다. 최근에 가장 널리 알려진 것은 구글의 causalImpact (https://github.com/google/CausalImpact) 와 페이스북의 prophet (https://github.com/facebook/prophet) 이다. 이 두 패키지의 특징 및 한계점은 다음과 같다.
causalImpact: 프로모션에 영향을 받는 지표와 그렇지 않은 지표 두 개를 제공하고 이 둘 간의 관계를 토대로 프로모션의 효과를 추정하는 방식이다. 목적 자체가 프로모션 효과를 추정하기 위함이기 때문에 특정 프로모션의 효과를 다양한 측면에서 직관적으로 추정해주는 장점이 있다. 하지만 앞서 언급했듯이 프로모션 효과를 분석하려면 대조군 역할을 하는 지표가 필요하다. 예를 들어 구글과 같은 글로벌 기업의 경우 어떤 프로모션을 특정 국가에만 실시할 수 있을 것이다. 이 경우 해당 국가의 프로모션 효과를 추정하기 위해 대조군으로 다른 국가 지표를 둘 수 있다. 만약 이런 식의 프로모션 진행이 어려운 상황이라면 이 패키지를 이용하기는 어렵다.
prophet: 별다른 튜닝 없이도 쉽게 시계열 예측 모델을 만들 수 있는 장점이 있다. 그러나 이 패키지는 시계열 예측에 초점을 맞췄기 때문에 특정 프로모션의 효과를 추정하는 목적으로 사용하기에는 다소 불편하다.
그래서 우리도 하나 만들어 봤습니다.
우리는 위 두 패키지들이 갖고 있는 특징을 참고하여, 프로모션의 효과를 추정하는 목적에 충실한 ‘promotionImpact’ 라는 R 패키지를 만들었다 (https://github.com/ncsoft/promotionImpact). promotionImpact의 주요 특징은 다음과 같다.
- 프로모션 정보와 시계열 지표 데이터를 넣어주면 알아서 회귀 모델을 생성해 준다. 따라서 사용자가 일일이 프로모션 정보를 회귀 모델에 맞게 변환할 필요가 없다. 즉, 번거로운 전처리 작업을 자동화했다.
- 직관적인 모델 해석 정보를 제공한다. 보통 시계열 데이터에서 회귀 계수를 안정적으로 해석하려면 로그 변환 및 차분을 활용해야 한다. 그런데 이 경우 회귀 모델의 계수를 다시 직관적으로 해석하려면 번거로운 변환 작업이 필요하다. promotionImpact 에서는 효과 추정에 필요한 회귀 계수 변환 작업 역시 자동으로 처리해 준다.
- 시간에 따른 프로모션 효과의 변화를 고려한 모델을 만들어 준다. 우리의 경험에 의하면 프로모션 효과는 프로모션 진행 기간 동안 계속 변한다 (그림 2). 예를 들어 어떤 프로모션은 개시 첫 날에 가장 효과가 좋으며 시간이 지날수록 그 효과가 점점 감소한다. 반면 어떤 프로모션은 개시 첫날은 별로 효과가 없다가 시간이 지날수록 입소문(viral)을 통해 점점 효과가 커지기도 한다. 이 경우 프로모션 진행 여부를 단순히 0 또는 1로 표현하는 더미 변수 방식을 사용하기 보다는 이런 시간에 따른 변화를 예측 변수에 반영해 주는 것이 더 좋을 것이다 (그림 3). promotionImpact 에서는 시간에 따라 프로모션 효과 변화를 smoothing function을 통해 추정해 준다.
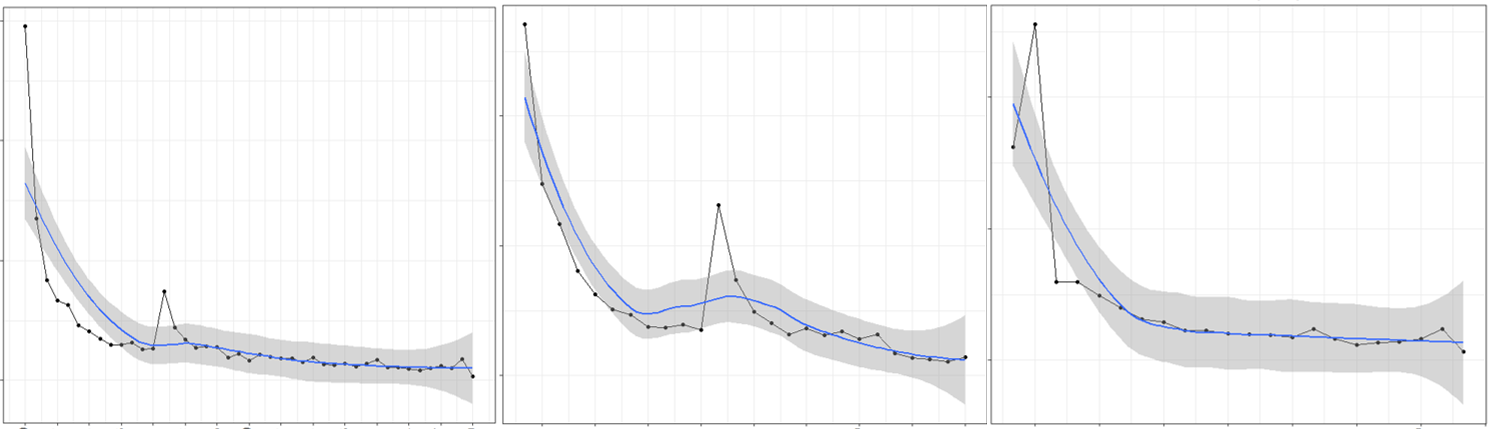 [그림 2] 다양한 프로모션의 기간별 매출 변화 예시
[그림 2] 다양한 프로모션의 기간별 매출 변화 예시
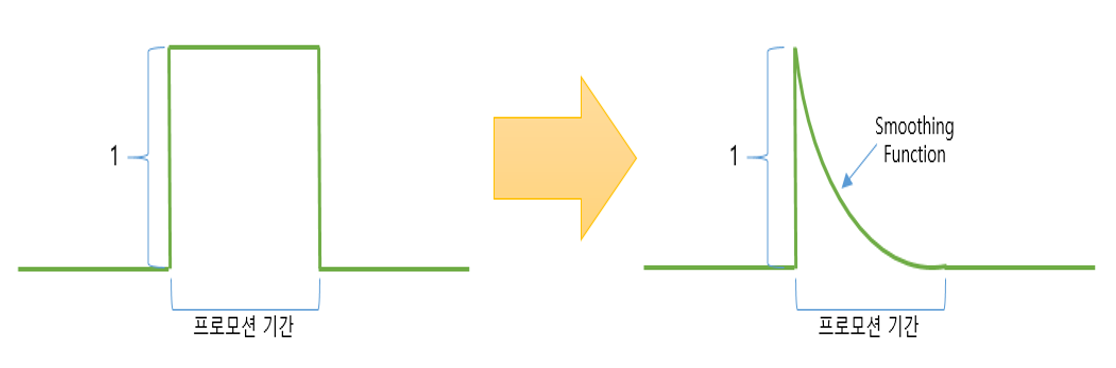 [그림 3] 시간에 따른 프로모션 효과 변화를 표현하려면 더미 변수 방식 (왼쪽) 보다 smoothing function 방식 (오른쪽) 이 더 적절함
[그림 3] 시간에 따른 프로모션 효과 변화를 표현하려면 더미 변수 방식 (왼쪽) 보다 smoothing function 방식 (오른쪽) 이 더 적절함
참고로 promotionImpact는 회귀 분석 시 추세와 주기성 정보를 추출할 때 내부적으로 prophet 을 사용한다. 시계열 데이터는 추세나 주기성을 잘 관리하는 것이 중요한데, 우리가 실험해 본 바에 의하면 prophet 은 이런 신호를 비교적 잘 추정해 준다. 그래서 prophet이 가진 장점은 최대한 활용하는 대신 프로모션 효과 추정 기능에 집중했다.
설치 방법
promotionImpact는 엔씨소프트 깃헙 (https://github.com/ncsoft/promotionImpact) 을 통해 설치할 수 있다. 설치 방법은 다음과 같다.
devtools::install_github("ncsoft/promotionImpact")
만약 아래 패키지들이 이미 설치되어 있다면, promotionImpact 를 설치하기 전에 이 패키지들은 삭제하고 설치해야 한다 (아래 패키지들은 promotionImpact 를 설치할 때 같이 설치된다).
- prophet
- Rcpp
- RcppEigen
- rstan
함수 설명
프로모션 효과를 분석하는 함수는 promotionImpact() 이다. 여기에는 많은 파라미터들이 있는데 각각이 의미하는 바는 다음과 같다.
- data: 분석할 시계열 지표 데이터
- promotion: 프로모션 일정 정보가 담긴 데이터
- time.field: ‘data’ 에서 날짜 정보가 담긴 필드명 (디폴트는 ‘date’)
- target.field: ‘data’ 에서 종속 변수 필드명 (디폴트는 ‘value’)
- dummy.field: ‘data’ 에서 프로모션 외에 지표에 영향을 주는 기타 이벤트 정보를 담고 있는 필드명
- trend: 모델에 추세 패턴을 반영하고 싶으면 TRUE, 아니면 FALSE (디폴트는 TRUE)
- trend.param: 추세 패턴 모델링 시 유연성을 조정하는 파라미터 (디폴트 0.5)
- period: 모델에 주기 패턴을 반영할 때 며칠 주기인지를 지정하는 파라미터. 단위는 ‘일’ 이며 만약 이 값을 ‘auto’로 지정하면 모델이 주기를 알아서 추정한다. 주기성이 없는 데이터라면 이 값을 NULL 로 지정하면 된다. (디폴트는 ‘auto’)
- period.param: 주기 패턴 모델링 시 유연성을 조정하는 파라미터 (디폴트는 3)
- structural.change: 분석할 지표가 외부의 어떤 사건 (예: 경쟁 제품 출시) 으로 인한 구조 변화가 있다고 판단되면 TRUE, 아니면 FALSE (디폴트는 FALSE)
- var.type: 프로모션 진행 기간 동안 효과가 변하지 않는다면 ‘dummy’, 변한다면 ‘smooth’ 지정 (디폴트는 ‘smooth’)
- smooth.except.date: var.type을 ‘smooth’ 로 했을 경우, 변화 추정 시 제외하고 싶은 일자가 있다면 해당 일자를 지정하는 파라미터. 예를 들어 월초 효과가 영향을 크게 미치는 지표의 경우 프로모션 기간 중에 ‘월초’가 들어가 있다면 이 파라미터에 ‘01’ 을 추가하여 변화 추정 과정에서 제외하는 것이 더 좋다. 만약 그렇지 않으면 해당 프로모션이 월초에 매우 효과가 좋은 것처럼 잘못 추정할 수 있다. (디폴트는 NULL)
- smooth.bandwidth: 프로모션 효과 변화를 추정하는 smooth function 에 사용하는 하이퍼 파라미터 (디폴트는 2)
- smooth.origin: smooth function 적용 대상을 지정해 주는 파라미터. 만약 모든 프로모션에 대해 동일한 smooth function 을 적용하고 싶다면 ‘all’, 각 프로모션 유형 별로 smooth function을 적용하고 싶다면 ‘tag’ 지정 (디폴트는 ‘all’)
- smooth.var.sum: 같은 유형의 프로모션이 기간이 겹쳐서 진행되는 경우, 겹치는 기간의 프로모션 변수를 합산하고 싶다면 TRUE, 더 최근에 진행된 프로모션의 변수 값으로 대체하고 싶다면 FALSE (디폴트는 TRUE)
- logged: 종속 변수를 로그 변환할지 여부 지정. TRUE 이면 종속 변수를 로그 변환한 후 회귀 모델을 적용하게 되며 이 때 프로모션의 영향력은 비율(%)로 표현된다. (디폴트는 TRUE)
- differencing: 차분을 할지 여부를 지정하는 파라미터. 만약 모델링 대상이 되는 지표가 자기 상관성이 있다면 이 파라미터를 TRUE로 해야 함 (디폴트는 TRUE)
연습용 예제 데이터
promotionImpact 패키지에는 사용자가 모델링 테스트에 사용할 수 있는 예제 데이터가 같이 제공된다.
sim.data
프로모션 효과 추정을 위한 시계열 매출 데이터이다. 스키마는 다음과 같다.
- dt: 일자 정보
- simulated_sales: 매출 지표
> head(sim.data)
dt simulated_sales
1 2015-02-11 1601948810
2 2015-02-12 2048650675
3 2015-02-13 2288870304
4 2015-02-14 2132470451
5 2015-02-15 1633739658
6 2015-02-16 2586956583
sim.promotion
효과 추정 대상이 되는 프로모션 일정 데이터이다. 다음과 같은 정보로 구성된다.
- pro_id: 프로모션 아이디
- start_dt: 해당 프로모션의 시작 일자
- end_dt: 해당 프로모션의 종료 일자
- tag_info: 프로모션의 유형. promotionImpact 에서는 이 tag_info 의 유형별로 효과를 추정하게 된다. 효과 추정 신뢰도를 높이려면 같은 tag_info 값을 갖는 프로모션들이 여러 개 있는 것이 좋다.
> head(sim.promotion)
pro_id start_dt end_dt tag_info
1 pro_1_1 2015-02-16 2015-03-14 A
2 pro_1_2 2015-06-07 2015-06-25 A
3 pro_1_3 2015-09-17 2015-10-21 A
4 pro_1_4 2015-12-26 2016-01-22 A
5 pro_1_5 2016-02-24 2016-03-12 A
6 pro_1_6 2016-05-18 2016-06-12 A
sim.promotion.sales
sim.promotion 자료에 추가적으로 각 프로모션별 관련 상품 매출 정보(payment)가 일자별로 집계된 자료이다. 프로모션 효과를 분석할 때 상품 매출 정보가 꼭 필요한 것은 아니지만, 만약 제공된다면 각 프로모션 효과의 시간에 따른 변화를 추정하는 참고 자료로 사용된다. 만약, promotionImpact 에서 프로모션 효과의 변화를 추정할 때 (즉, var.type = ‘smooth’ 인 경우), 프로모션 정보에 매출 정보가 있으면 smooth function 적용 시 이 값을 사용하며, 그렇지 않으면 회귀 모델의 잔차를 이용하여 변화를 추정한다.
> head(sim.promotion.sales)
pro_id start_dt end_dt tag_info dt payment
1 pro_1_1 2015-02-16 2015-03-14 A 2015-02-16 1033921614
2 pro_1_1 2015-02-16 2015-03-14 A 2015-02-17 971764194
3 pro_1_1 2015-02-16 2015-03-14 A 2015-02-18 765285484
4 pro_1_1 2015-02-16 2015-03-14 A 2015-02-19 830401468
5 pro_1_1 2015-02-16 2015-03-14 A 2015-02-20 649482501
6 pro_1_1 2015-02-16 2015-03-14 A 2015-02-21 509385712
프로모션 효과 분석 예제
다음은 샘플 데이터를 이용해 프로모션 효과를 분석한 예이다.
library(dplyr)
library(promotionImpact)
sim.data <- sim.data %>%
dplyr::mutate(month_start = ifelse(substr(as.character(dt),9,10) == '01', 1, 0))
pri <- promotionImpact(data=sim.data, promotion=sim.promotion,
time.field = 'dt', target.field = 'simulated_sales',
dummy.field = 'month_start',
trend = T, period = 30.5, logged = T, differencing = T)
위 코드를 실행하면 분석 결과는 ‘pri’ 객체에 저장되는데, 여기에는 다음과 같은 정보가 담겨있다.
effects
sim.promotion에 기록된 프로모션 유형별로 지표에 미치는 효과. 종속 변수는 로그 변환되었으므로 (즉, logged = T) 이 효과는 증가 혹은 감소율로 표시된다. 가령 아래 결과의 경우 A 유형의 프로모션은 평균적으로 매출을 19.65% 증가시키는 효과가 있다는 것을 의미한다.
> pri$effects
A B C D E
1 19.64531 13.59537 10.62033 7.903838 4.082812
model
회귀 분석 결과와 관련된 정보를 담고 있는 객체
- model: lm() 함수를 통해 나온 회귀 모델 결과 객체
> summary(pri$model$model)
Call:
"lm(data, formula = value~A+B+C+D+E+month_start+trend_period_value)"
Residuals:
Min 1Q Median 3Q Max
-0.43108 -0.05664 0.00896 0.06357 0.33618
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.010292 0.003621 -2.842 0.00458 **
A 0.601472 0.033776 17.808 < 2e-16 ***
B 0.430225 0.033865 12.704 < 2e-16 ***
C 0.339870 0.035449 9.587 < 2e-16 ***
D 0.257908 0.033964 7.594 7.43e-14 ***
E 0.134598 0.033731 3.990 7.11e-05 ***
month_start 0.323358 0.020761 15.575 < 2e-16 ***
trend_period_value 0.432882 0.263455 1.643 0.10069
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1101 on 949 degrees of freedom
Multiple R-squared: 0.4942, Adjusted R-squared: 0.4905
F-statistic: 132.5 on 7 and 949 DF, p-value: < 2.2e-16
- final_input_data: promotionImpact() 함수에 지정된 파라미터를 토대로 전처리 과정이 모두 끝난 최종 입력 데이터
- fit_plot: 실제 값과 모델의 예측값을 표시한 그래프 (그림 4)
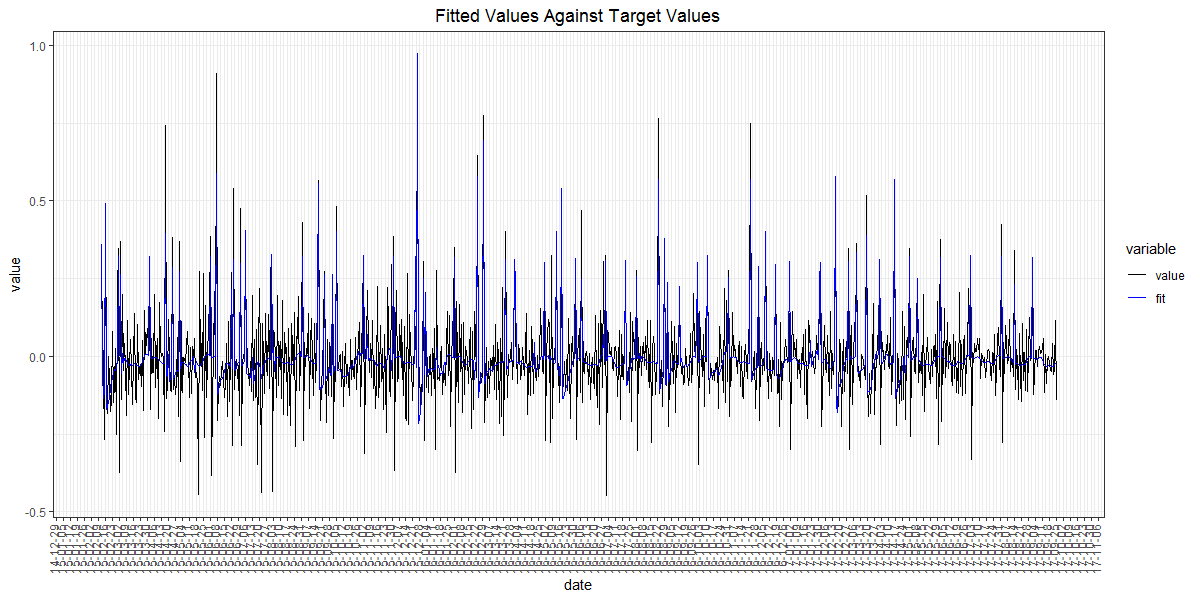 [그림 4] fit_plot 그래프 예시
[그림 4] fit_plot 그래프 예시
- trend_period_graph: 추세와 주기성을 표시한 그래프 (그림 5)
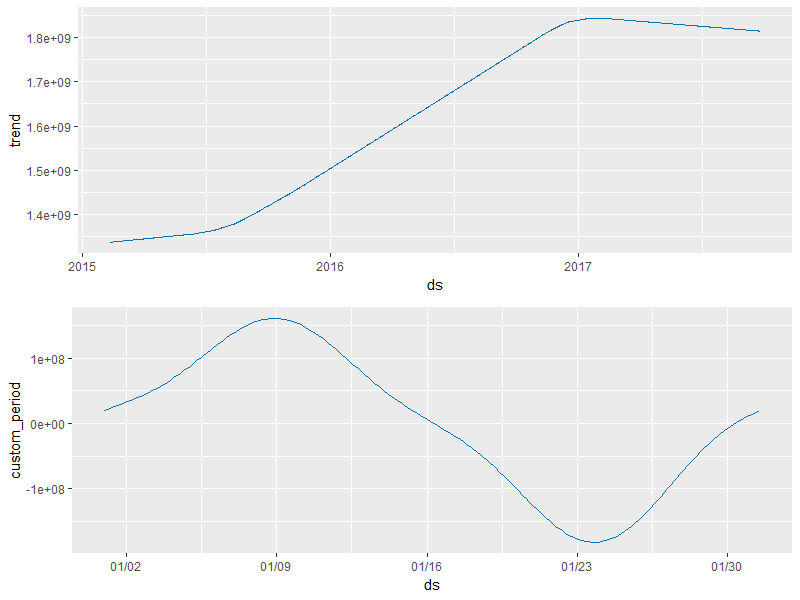 [그림 5] trend_period_graph 그래프 예시
[그림 5] trend_period_graph 그래프 예시
- trend_period_graph_with_target: 추세/주기성 그래프를 실제 데이터와 같이 표시한 그래프 (그림 6)
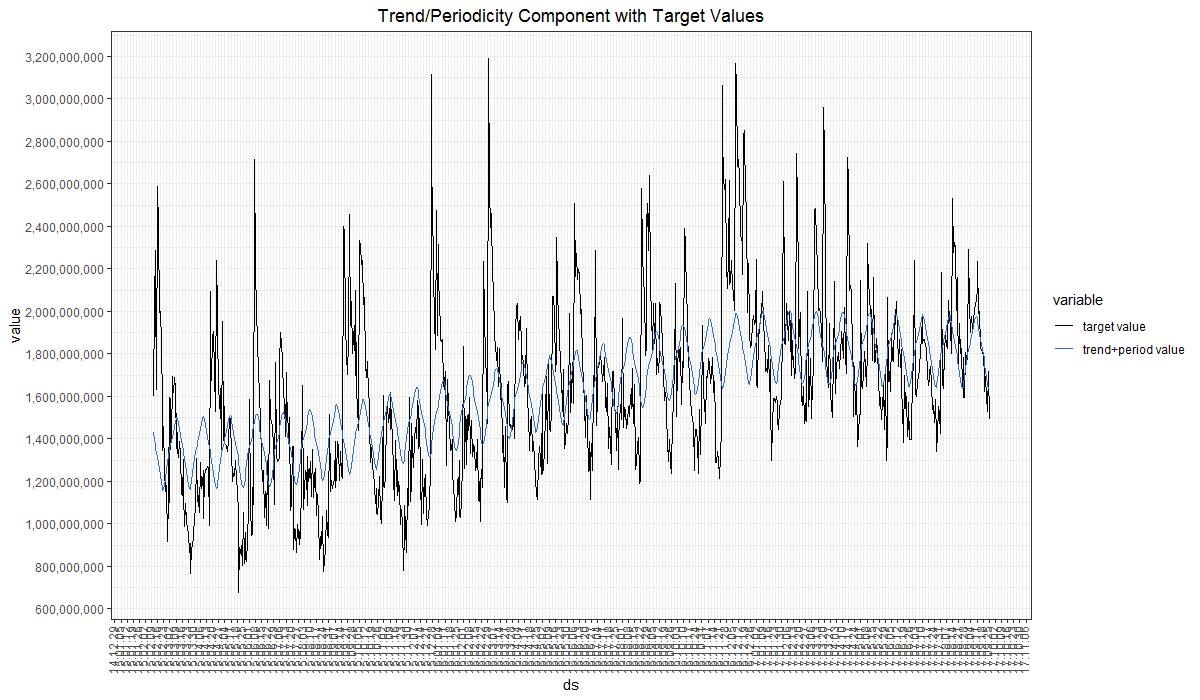 [그림 6] trend_period_graph_with_target 그래프 예시
[그림 6] trend_period_graph_with_target 그래프 예시
smoothvar
각 프로모션 효과 변화를 추정한 smooth function 관련 정보를 담고 있는 객체
- data: 프로모션 유형별로 smooth function 을 적용하여 나온 결과를 담고 있는 데이터
- smooth_except_date: 함수 실행 시 ‘smooth.except.date’ 파라미터에 지정한 값
- smoothing_graph: 사용된 smooth function 그래프. 예를 들어 아래 그래프는 전체 프로모션들에 대해 일자에 따른 효과의 평균적인 변화를 그래프로 나타낸 것이다 (그림 7). 만약 smooth.origin = ‘tag’로 지정한 경우에는 각 프로모션 유형별 그래프가 반환된다. (그림 8)
- smoothing_means: 유형별 smooth function 함수값
- smooth_value: 각 프로모션별로 계산된 smoothing 변수값
- smooth_value_mean: 위 smooth_value에 대한 각 유형별 평균값
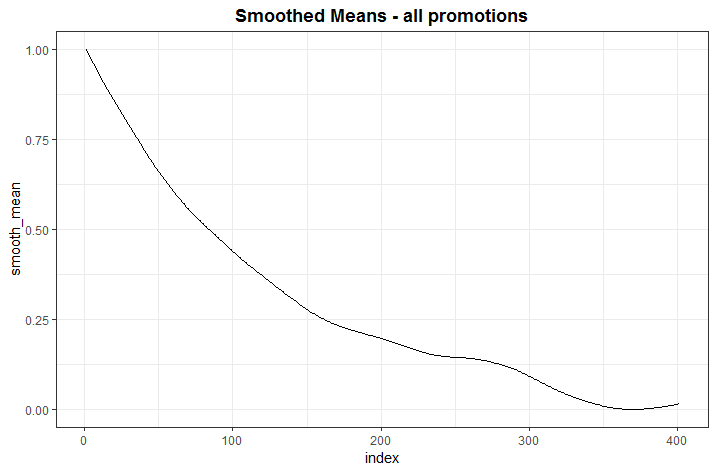 [그림 7] 전체 프로모션에 대한 평균적인 smooth function 그래프
[그림 7] 전체 프로모션에 대한 평균적인 smooth function 그래프
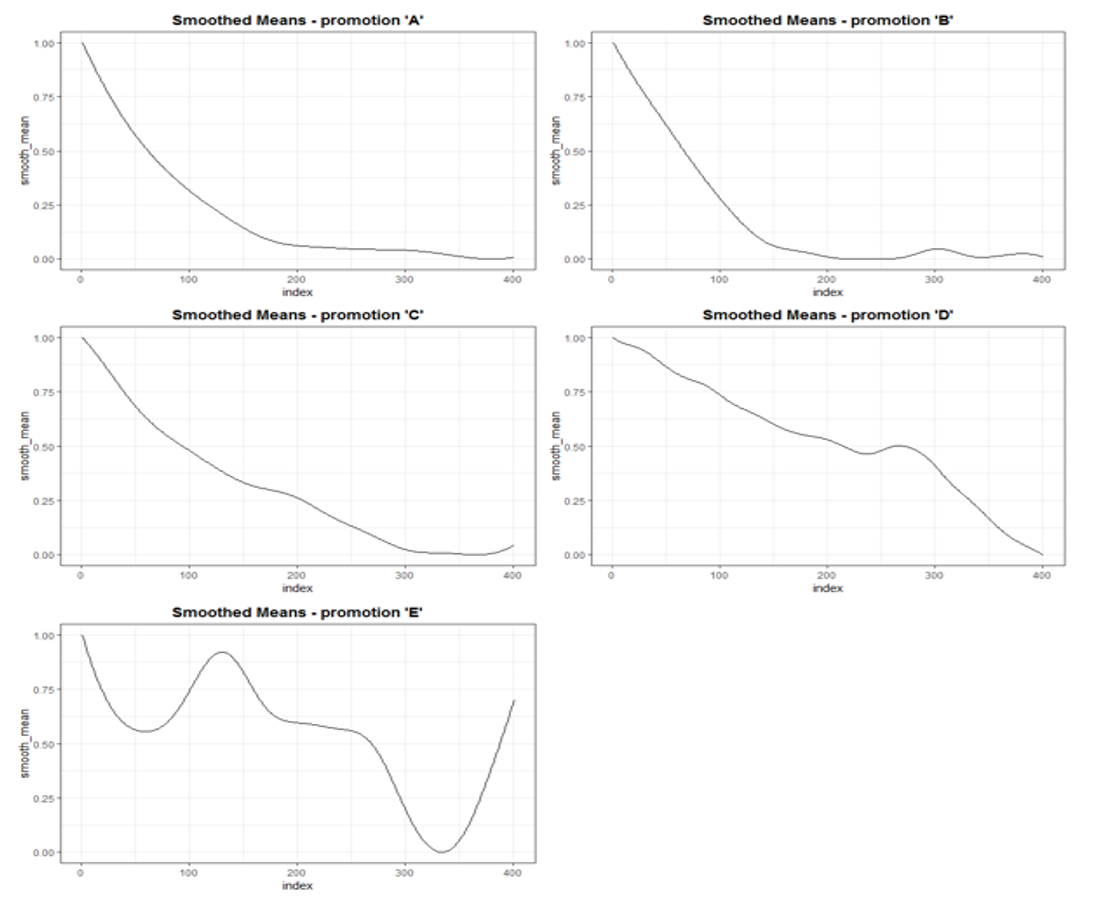 [그림 8] 만약 smooth.origin 파라미터를 ‘all’ 대신 ‘tag’ 로 하면 smooth function 을 유형별로 추정함
[그림 8] 만약 smooth.origin 파라미터를 ‘all’ 대신 ‘tag’ 로 하면 smooth function 을 유형별로 추정함
마치며
‘측정할 수 없는 것은 관리할 수 없다.’는 말이 있다. 좋은 마케팅 정책을 세우고 프로모션을 활발히 수행하는 것도 중요하지만 이렇게 진행한 프로모션이 실제 어떤 효과가 있었는지 확인하지 않는다면 서비스를 잘 운영하고 개선하기 어려울 것이다. 그래서 업계에서는 현황 파악을 위해 다양한 지표를 집계하고 있지만 막상 그 지표를 보고 현재의 상태를 정확히 해석하는 것은 쉽지 않다. 그 이유는 단순히 어떤 수치만 갖고는 가치 평가를 하기 어렵기 때문이다.
promotionImpact 는 집계된 지표를 토대로 여러 가지 프로모션들의 효과를 추정하는데 필요한 데이터 전처리 및 회귀 분석 과정을 최대한 쉽게 하기 위해 만든 R 패키지이다. 아직 보완해야 할 점이 많이 있으며 부족한 부분들은 계속 개선해 나갈 계획이다. 이 과정에서 많은 분들이 패키지를 사용해 보고 피드백을 준다면 더욱 완성도 높은 라이브러리로 발전해 나갈 수 있으리라 생각한다.
마지막으로 promotionImpact 의 회귀 분석 기법에 대해 좀 더 구체적인 내용이 궁금하신 분은 2019년 1월 말에 발간 예정인 마이크로소프트웨어 (https://www.imaso.co.kr) 395호를 확인하시기 바란다.