

자연어처리와 HR analytics
자연어처리가 각광을 받는 이유에는 여러가지가 있겠지만, 해당 분야가 “언어” 를 다루는 분야라는 사실이 적지 않은 비중을 차지하리라 생각된다. 언어는 인간 사이 발생하는 소통 중 가장 많은 정보를 짧은 시간 내에 전달할 수 있는 독보적인 수단이며, 인류는 오랜 시간 언어를 활용해 다양한 사회적 활동을 수행해 왔다. 다시 말해 자연어처리는 인간이 축적해온 다양한 문화적, 사회적, 기술적 데이터를 효과적으로 활용할 수 있는 수단들 중 하나인 셈이다. 자연어처리는 기본적으로 언어와 관련된 데이터가 존재하는 모든 분야에 적용이 가능한데, 필자가 소속된 조직에서는 그 중에서도 HR analytics와 접목될 수 있는 자연어처리에 대한 영역에 관심을 갖고 있다. 이번 글에서는 이러한 관심을 바탕으로 찾아본 자연어처리 분야에서 관심을 갖고 해결하고자 연구되고 있는 세부 도전과제들과, 해당 과제가 HR analytics에 어떤 영향을 줄 수 있을지에 대해 이야기해 보고자 한다.
자연어처리 과제와 모델, 학습 예시
자연어처리 모델의 구성은 1) 어떤 데이터로 2) 어떤 과제를 3) 어떻게 학습하여 해결할지를 결정하는 과정에서 구체화 되어간다. 이에 대한 내용은 2018년 공개된 BERT에 잘 요약되어 있다. 사실 BERT에서 요약한 것은 그들의 사전학습 모델을 전이학습에 적용하여 어떤 문제들을 해결할 수 있는가에 대한 설명이었지만, 현존하는 NLP 과제의 많은 부분을 포함하고 있어 각 과제에 대한 파악과 적용 사례를 살펴보기에 적절한 지표로 생각된다. 하지만 해당 논문에서는 데이터셋과 딥러닝 모델 구성 방식 관점에서 설명을 전개하였는데, 이는 공개되어있는 데이터셋의 구조와 목적에 맞는 딥러닝 모델을 4종류로 구성한 후 여러 데이터로 해당 모델의 성능을 검증하기 위함이였다. 우리 글에서는, 본 글의 초점에 맞게 딥러닝 모델의 각 구조와 상응하는 데이터셋으로 어떤 문제를 해결할 수 있는지에 대한 관점으로 다시 한 번 정리하였다.
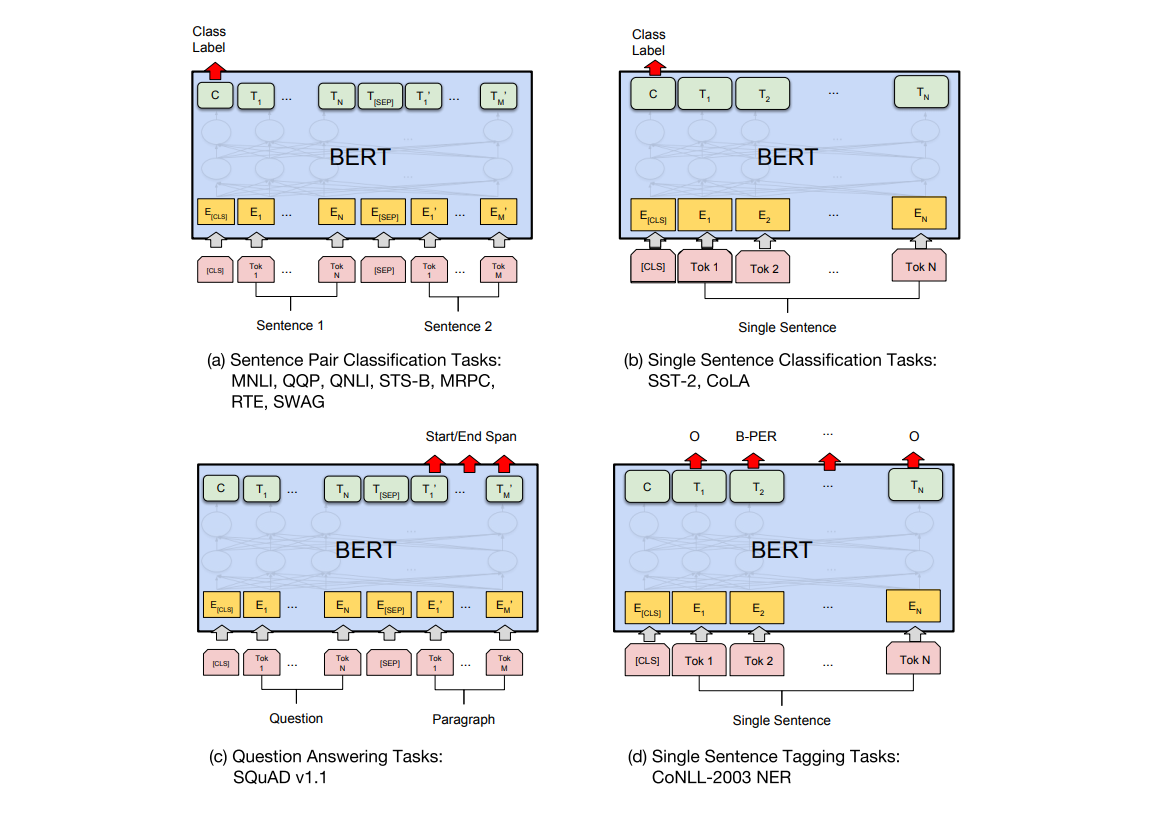
- (a) Sentence Pair Classification Tasks
- MNLI (Multi-Genre Natural Language Inference) : 자연어추론
- QQP (Quora Question Pairs) : 두 질문이 같은 질문인지 아닌지 구분하는 문제
- QNLI (Question-answering Natural Language Inference) : 질의응답 (Q, A) 구조로 되어있으며, A가 질문 Q에 대한 대답으로 적합한지를 분류
- STS-B (Semantic Textual Similarity) : 의미론적 문장 유사도 판단 문제
- MRPC (Microsoft Research Paraphrase Corpus) : 문장 유사도 문제
- RTE (Recognizing Textual Entailment) 텍스트 함의 인식
- SWAG (Situations With Adversarial Generations) : 기초 상식 추론
- (b) Single Sentence Classification Tasks
- SST-2 (Stanford Sentiment Treebank) : 감정분석 데이터셋
- CoLA (The Corpus of Linguistic Acceptability) : 언어적 용인 가능성 판별 문제
- (c) Question Answering Tasks
- SQuAD v1.1 : Stanford Question Answering Dataset : 질의응답 문제
- (d) Single Sentence Tagging Tasks
- CoNLL-2003 NER (Named Entity Recognition) : 자연어에서 이름을 찾아내는 문제
(a) 문장 페어(pair) 분류 문제 (Sentence Pair Classification Tasks)
BERT의 따르면 그들은 BERT로 해결할 수 있는 4 종류의 학습 방법에 대해 설명하고 있다. 여기에서 각 모델에 대한 구분은 데이터로의 input과 output의 구성에 따른 차이이다. 먼저 (a) Sentence Pair Classification Tasks는 두 개의 sentences를 [SEP] 토큰으로 구분해 pair의 형태로 입력하여 출력으로 class label을 받는 구조이다. 이 구조는 서로 다른 두 개의 sentences로 부터 (True or False) 등과 같이 단순한 정보를 추출하는 과제에 적합하다. 해당 구조로 학습하기에 적합한 데이터셋으로는 MNLI, QQP, QNLI, STS-B, MRPC, RTE, SWAG이 언급되어 있는데, 이를 과제 종류에 따라 분류하면 아래와 같이 두 종류로 구분할 수 있다.
- 자연어 추론 : MNLI, QNLI, RTE, SWAG
- 문장 유사도 확인 : QQP, STS-B, MRPC
언급한 자연어추론을 위한 데이터셋 (MNLI, QNLI, RTE, SWAG 등) 은 모두 비슷한 포멧을 갖고 있는데, 2종의 sentences로 구성된 컬럼과, 1종의 class label 컬럼을 갖고 있다. 여러 데이터셋 중 QNLI의 예를 확인해보자. 아래 예시에서 Question은 질문, Answer은 답변이며 Class label은 Answer이 Question에 대한 답변이 될 수 있는지를 나타낸다.
| 구분 | 설명 |
|---|---|
| Question | When did the third Digimon series begin? (세 번째 디지몬 시리즈는 언제 시작되었습니까?) |
| Answer | Unlike the two seasons before it and most of the seasons that followed, Digimon Tamers takes a darker and more realistic approach to its story featuring Digimon who do not reincarnate after their deaths and more complex character development in the original Japanese.(디지몬 테이머즈(*세 번째 디지몬 시리즈)는 죽은 뒤 되살아나지 않는 디지몬과 좀 더 복잡한 캐릭터 설정으로 인해 이전 두 시즌과 그 이후의 대부분의 시즌과 달리 어둡고 더 현실적인 스토리를 보여줍니다.) |
| Class label | entailment / not_entailment |
또한 (a) 구조는 문장에 대한 유사도 여부를 판별하는 모델로도 학습이 가능한데, 이 경우 입출력 데이터의 구조는 아래와 같다. 해당 데이터는 QQP의 예시이며, 결과적으로 딥러닝 모델은 입력 문장 1과 입력 문장 2가 같은 의미의 문장인지 아닌지에 대한 class label을 기반으로 weight propagation을 수행하여 학습하게 된다.
| 구분 | 설명 |
|---|---|
| Sentence 1 | Why are so many Quora users posting questions that are readily answered on Google?(왜 많은 Quora 유저들은 Google을 통해 쉽게 답을 찾을 수 있는 질문을 올릴까요?) |
| Sentence 2 | Why do people ask Quora questions which can be answered easily by Google?(왜 사람들은 Google에서 쉽게 답변받을 수 있는 질문을 Quora에서 할까요?) |
| Class label | similar / different |
(b) 단일 문장 분류 문제 (Single Sentence Classification Tasks)
두 번째 설명할 내용은 (b) Single Sentence Classification Tasks를 해결하기 위한 구조이다. 본 구조는 사실 가장 기본적인 Text classification에 사용되는 구조이며, 단일 sentence 입력을 받아 class label을 출력하는 구조로 되어있다. 다시 말해 단일 문장에 대한 단순한 판단을 필요로 하는 경우에 적합하다. 해당 구조로 학습하기에 적합한 데이터셋으로는 SST-2와 CoLA가 존재하며, 이를 과제 종류에 따라 분류하면 아래와 같다.
감정 분석 : SST-2
언어적 용인 가능성 판별 : CoLA
(b) 구조로 학습할 수 있는 데이터는 단일 문장과 단일 class label를 입력 받아 학습하는 구조이다. 예시는 SST-2 데이터셋이며, 입력 문장과 해당 문장이 긍정문인지 부정문인지를 나타내는 class label로 구성이 되어있다.
| 구분 | 설명 |
|---|---|
| Sentence | that loves its characters and communicates something rather beautiful about human nature(그의 캐릭터들을 사랑하고 인간 본성에 대한 아름다음을 전달한다) |
| Class label | positive / negative |
언어적 용인 가능성을 판별해주는 딥러닝 모델 역시 (b) 구조로 학습하게 되며, 입력 문장과 해당 문장이 언어적으로 용인이 가능한지 여부를 판별해주는 class label로 구성이 되어있다. 해당 문장은 CoLA 데이터셋의 예시이다.
| 구분 | 설명 |
|---|---|
| Sentence | In which way is Sandy very anxious to see if the students will be able to solve the homework problem? |
| Class label | acceptable / unacceptable |
(c) 질의응답 문제 (Question Answering Tasks)
다음으로 소개할 (c) Question Answering Tasks의 경우에는 단어 자체에서 과제의 유형을 추론할 수 있듯, 질의응답에 관한 데이터에 사용되는 구조이다. 관련 데이터셋으로는 SQuAD가 존재하며, (a)와 같이 두 개의 sentences를 입력해 단일 sentence를 출력 받는 구조로 되어있다. 사실 (a) 에서도 질의응답 관련 데이터셋 (QNLI) 이 등장하는데, 모델의 출력이 class label이냐, sentence이냐에 따라 차이가 있다. (a) 구조에서는 출력 포멧이 class label로, 입력된 질문에 대한 응답으로써 각 pair가 적절한지를 확인하는 과제였다면, (c) 구조로 해결할 수 있는 과제는 질문에 대한 응답을 문장 형태로 출력하여 질문에 대한 보다 직접적인 응답을 제공한다. SQuAD의 경우 Context와 Question을 입력으로 하여 Answer을 출력하는 방식으로 학습을 진행하며, 여기에서 Context는 Question에 대한 Answer를 추론하기에 배경 정보가 담겨있는 문단에 해당한다.
- 질의응답 : SQuAD v1.1
(c)는 아래와 같은 데이터셋을 학습하여 동작한다. 해당 데이터는 SQuAD v1.1에 해당하는 데이터로 Context와 Question을 입력으로 받고, Answer을 label로 하여 학습을 수행한다. 예시에서 나타나는 바와 같이, Question은 Context에 포함된 내용에 대한 질문으로 구성되어 있으며, Answer은 해당 질문에 대한 정답으로 구성된다.
| 구분 | 설명 |
|---|---|
| Context | Architecturally, the school has a Catholic character. Atop the Main Building’s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend “Venite Ad Me Omnes”. Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary. |
| Question 1 | Where is the headquarters of the Congregation of the Holy Cross?(the Congregation of the Holy Cross의 본부는 어디에 있습니까?) |
| Answer 1 | {“text”: “Rome”, “answer_start”: 119} |
| Qeustion 2 | What is the oldest structure at Notre Dame?(노트르담에서 가장 오래된 건축물은 무엇입니까?) |
| Answer 2 | {“text”: “Old College”, “answer_start”: 234} |
| … | … |
(d) 문장 태깅 문제 (Single Sentence Tagging Tasks)
마지막으로 언급된 (d) Single Sentence Tagging Tasks는 단일 문장을 입력받고, 해당 문장에 포함된 token 들에 대해 tagging을 하는 과제에 적합한 구조이다. 논문에 언급된 CoNLL-2003 NER은 Named Entity Recognition 문제를 위한 데이터셋이며 자연어 문장에서 개체명 (Named Entity)를 찾아내는 문제에 해당한다. 개체명의 종류로는 인명, 단체, 장소, 의학 코드, 시간 표현, 양, 금전적 가치, 퍼센트 등이 해당한다.
- 개체명 인식 : CoNLL-2003 NER (Named Entity Recognition)
마지막으로 개체명 인식을 위한 데이터셋은 아래와 같이 구성되어있다. BERT 논문에서 예로 들었던 CoNLL-2003 NER 데이터셋이며, sentence의 각 단어 (또는 token) 에 대한 label로 구성되어 학습된다. 여기에서 O는 outside of named entity로 개체명에 해당하지 않음을 의미하며, PER은 인명, LOC은 지역, ORG는 기관, MICS는 특정되지 않은 개체명을 의미한다.
| 구분 | 설명 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sentence | EU | rejects | German | call | to | boycott | British | lamb | . |
| Tagging | B-ORG | O | B-MISC | O | O | O | B-MISC | O | O |
자연어처리 과제와 응용
지금까지 자연어처리 모델로 해결할 수 있는 과제들을 BERT에 언급된 목록을 활용해 열거해 보았다. 그렇다면 각각의 과제를 현업에는 어떻게 적용할 수 있을까? 아래 제시된 표를 통해 자연어처리의 HR Analytics관점에서의 활용점을 나열한다.
| 문제 | 데이터 분석 적용 사례 |
|---|---|
| 자연어 추론 | 학벌, 인종, 성별 유추 가능한 내용 존재할 경우 필터링 |
| 문장 유사도 확인 | 유사 이력서/지원자 검색 등 |
| 감정분석 | 개인별 업무 평가나 코멘트 의미 파악에 활용 가능 |
| 언어적 용인 가능성 | 각종 문법 검사기나 표현 추천 기능에 활용중 |
| 질의응답 | 챗봇 기능을 활용해 모의 면접이나, 스트레스 관리 등에 활용할 수 있을 것 |
| 개체명 인식 | 평가에서 핵심 단어를 추출 및 요약하는 용도로 활용 |
자연어 추론
먼저 자연어 추론의 경우 인사데이터 분석 관점에서 살펴봤을 때 특정 이력서에 학벌, 인종, 성별 등 민감한 정보가 포함되었는지에 대한 정보를 찾아내는데 사용할 수 있을 것이다. 사실 이런 정보는 굉장히 찾기 쉬우면서도 또한 어려운 부분일 수 있다. 해당 표현이 직접적인 키워드와 함께 언급된 경우에는 단순히 금지어 사전을 만들어 검색함으로 필터링 할 수 있겠지만, 우회적으로 표현된 경우에는 찾기가 어려워지기 때문이다. 예를 들어, 이력서에 아래와 같은 두 가지 표현이 올라왔다고 가정하자.
- 저는 외동아들로 태어나 …
- 대학교 1학년을 마친 후 카투사에 합격해 …
해당 사례에서, 전자의 경우 문장 자체에 지원자의 성별을 나타내는 단어가 등장하기 때문에 면접관이 이력서를 열람하기 전에 해당 사항에 대해 사전 필터링을 수행할 수 있다. 하지만 후자의 경우에는 어떤가? 본문에 성별을 직접적으로 판단할 수 있는 단어는 존재하지 않고, 카투사에 합격했다는 문장으로 지원자가 남성임을 유추해야 되는 상황이다. 따라서 머신에게 자연어를 이해할 수 있도록 학습하는 방법론들의 적용이 요구된다.
문장 유사도 확인 + 언어적 용인 가능성
문장 유사도와 언어적 용인 가능성은 회사 지원자들의 편의를 위해 활용될 수 있을 것이다. 예를 들면, 나와 유사한 기술 혹은 적성을 갖고 있는 선배 지원자들의 사례를 조회하는 기능이나, 해당 직무 관련 질문들 중 유사한 질문들을 검색하여 지원자에게 보여주는 기능으로 활용될 수 있다. 또한 언어적 용인 가능성의 경우, 에디터 보조 서비스로 작문 시 오타 점검, 문맥 확인등을 해주어 보다 완성도 높은 글을 작성할 수 있도록 도움을 줄 수 있다. 실제 영어 버전으로 구현된 서비스의 경우, 조건에 따라 formal 및 informal 한 영작 옵션을 설정할 수 있고, 문체까지 설정해주는 기능이 존재하여 오탈자나 동의어 추천 기능 등이 매우 유용하게 사용되고 있다. 뿐만 아니라 작성한 문장에 대한 가독성과, 어휘 수준을 체크해주는 기능을 통해 세밀한 피드백을 받을 수 있어 영작 공부 시에도 많이 활용된다.
실제 서비스로 적용된 사례를 살펴보면 이러한 기능은 공고를 게시하는 회사 측에도 도움이 되고 있다. T모 서비스의 경우 자연어 처리(NLP) 로 공고의 뉘앙스를 점검하는 서비스로, 공고문에 의도치 않게 포함된 부정적인 이미지를 사전에 찾아내어 해소하는 역할을 수행한다. 해당 서비스를 통해 공고 작성자는 지원자들에게 보다 매력적으로 보일 수 있도록 채용 공고를 첨삭받을 수 있다. 예를 들어, 특정 성별을 주요 채용 대상으로 둘 때 같은 의미라도 뉘앙스에 따라 공고의 매력도가 다르다는 사실을 알려주거나 하는 식이다. 해당 서비스에서는 이 기능을 통해 자격을 갖춘 후보자의 지원이 30% 증가했다고 밝히고 있다. 맥도날드, 슬랙, 스포티파이 등 여러 기업에서 해당 서비스를 사용 중 이라고 한다.
감정분석 + 개체명 인식
감정분석과 개체명 인식은 코멘트를 기반으로한 마케팅에서 활용된 사례가 있으며, 이를 평가 데이터에 접목할 경우 코멘트를 요약하는 용도로 활용할 수 있다. 가령 개체명 인식을 통해 역량들에 대한 NER 태깅을 수행한 후, 감정분석을 통해 해당 역량에 대한 코멘트가 긍정 코멘트로 사용되었는지, 부정 코멘트로 사용되었는지를 확인하는 식이다. 사실 대부분의 직원들은 이미 실력이 검증되어 채용된 사람들일 것이나, 조직이나 업무적 특성에 따라 어떤 실력을 갖춘 사람을 더 우수한 인재로 바라보는가에는 차이가 생길 것이다. 따라서 이렇게 결과를 추출 후 높은 평가를 받는 직원들의 코멘트에 어떤 키워드들이 주로 나타나는지를 확인하면, 각 회사나 팀 단위에서 추구하는 인재상이나 리더십 모델에 대한 특징을 보다 구체적으로 확인할 수 있을 것이며, 추후 채용에도 이를 활용해 각 팀과 성향이 잘 맞는 인재를 채용할 수 있을 것이다. 예를 들면, 아래와 같은 코멘트에 대한 결과를 요약 및 추출할 수 있다.
| 원문 | 인식 개체명 | 주요 키워드 | 긍부정 |
|---|---|---|---|
| 직원1님(EMP)은 개발업무(SKIL)에 있어 우수한 역량을 바탕으로 솔선수범 하는 모습을 보여주셨습니다. | 직원1, 개발업무 | 우수한, 솔선수범 | 긍정 |
| 직원2님(EMP)은 원활한 인간관계(CAPA)를 바탕으로 동료들을 잘 다독여 주셨고, 그 결과 기한에 맞춰 작업을 완료할 수 있었습니다. | 직원2, 인간관계 | 원활한 | 긍정 |
질의응답
말 그대로 질의응답 기법을 활용해 지원자에게 채용 관련 실시간 Q&A 기능을 제공하거나, 실제 채용 프로세스에 접목하는 등의 효과를 기대할 수 있을 것이다. 실제로 M사와 W 외국 회사의 경우 NLP 기반 AI 인터뷰를 진행하고 있으며, 그들의 NLP 모델은 지원자의 의도, 문맥, 이해도 등을 파악하여 채용 데이터베이스에 자동으로 업데이트 하는 기능을 제공한다. 또한 지원자들의 이력서나 채팅 면접 시 발생된 지원자들의 특성을 요약해 어떤 직무에 적합할지를 판단해주는 기능을 갖고 있어 채용담당자들의 시간을 기하급수적으로 감축시킬 수 있다고 한다.
자연어 처리 기술을 이용한 HR Analytics 사례
일반적으로 평가제도에서는 직원의 성과 및 역량에 대해 등급을 매기는 정량 평가와 개선과 성장을 위한 피드백을 제공하는 정성 평가로 이루어진다. 우리는 자연어 처리 기술을 이용해 그 중 정성 평가에 대한 분석을 수행하였다. 정성 평가 데이터는 여러 종류의 평가 제도를 통해 수집되는데 일반적으로 생각하는 조직장이 조직원에게 하는 피드백 뿐 아니라, 동료간 피드백이나 조직원이 조직장에게 하는 피드백도 포함되어 있다.
우리는 분석을 위해 먼저 데이터 익명화를 수행하였다. 데이터 익명화는 분석가가 해당 피드백이 어떤 직원에 대한 코멘트인지를 알 수 없도록 이름이나 개인정보를 익명화 하는 과정이다. 익명화된 코멘트는 문장단위로 분리하여 감정분석을 수행하였다. 아무래도 평가 코멘트는 동료의 역량에 따라 피드백 성향이 달라질테니 이렇게 코멘트를 문장단위로 분리하여 감정분석을 하면 평가 등급에 따라 피드백의 양상이 얼마나 다르게 나타나는지 확인할 수 있으리라 생각했다. 즉, 성과가 좋은 동료에게는 좋은 피드백을, 개선이 필요한 동료들에게는 개선점에 대한 피드백을 줄텐데 그런 차이가 수치적으로 얼마나 차이가 나는지 확인하고 싶었다. 하위 표는 평가 등급에 따른 피드백 내 긍부정문 포함 비율을 확인한 것이다. 평가 등급은 1~5 등급으로 나뉘며 수치가 낮을수록 높은 평가를 의미한다.
우리가 활용한 감정분석 모델은 각 문장의 긍부정 여부를 [0, 1] 범주의 값으로 나타내는데 1에 가까울 수록 긍정, 0에 가까울 수록 부정을 의미한다. 우리는 긍부정 여부에 대한 임계값을 설정하여 긍부정 확률이 0.15 이하인 문장을 부정으로, 0.85 이상인 문장을 긍정으로 취급하였으며, 0.15~0.85에 해당하는 문장은 중도로 구분하였다. 이렇게 기준을 설정하고 등급에 따라 긍정 코멘트와 부정 코멘트 수치를 비교했을 때, 가장 역량 및 성과가 높은 1등급은 부정 코멘트의 수 대비 긍정 코멘트의 수가 약 46배 정도 많게 타나났다. 또한 해당 결과를 통해 평가자가 각 평가 등급의 차이를 얼마나 명확하게 인지하고 있는지를 수치로 확인해볼 수 있었다. 본 결과에서는 1등급과 2등급의 긍부정 비율 차이는 크지 않은 반면 2에서 3으로 내려가는 구간에서 해당 수치가 급격히 감소하였다. 각 등급의 차이는 동일하게 한 단계이나, 평가자는 체감상 1~2 등급의 차이를 2~3 등급의 그것과 다르게 생각한다고 추정된다. 본 주제와는 조금 다른 맥락이나, 해당 차이를 다른 방면에서 봤을 때도 마찬가지였다. 코멘트에 등장한 3-gram 명사 기준의 빈출 단어 유사도를 확인해 본 결과 역시 1~2등급 사이 유사도 보다 2~3등급 사이 단어 유사도가 더 낮게 나타났다. 이러한 결과는 향후 평가 등급 조정이나 등급별 보상 체계 등을 개선할 때 참고할 수 있다.
| 평가 등급 | (긍정/부정) 비율 |
|---|---|
| 1 | 46.32 |
| 2 | 34.73 |
| 3 | 17.25 |
| 4 | 1.28 |
| 5 | 0.31 |
더 나아가 자연어 처리 기술을 이용하면 평가 코멘트를 요약하는데 활용할 수 있다. 상기 분석에서 익명화를 수행할 때, 우리는 3종류의 태그를 활용하였는데 이는 각각 EMP, CAPA, SKIL이다. 여기에서 EMP는 익명화를 수행할 때 필요한 태그이고, 다른 두 태그는 역량 또는 기술에 해당하는 태그이다. 역량 및 기술 태그를 활용하면 해당 문장이 어떤 역량 및 기술에 대한 코멘트인지를 확인할 수 있으며, 이를 활용하면 각 사원들의 장점과 역량들을 아래와 같이 정보화 할 수 있다.
| 원문 | 직원 ID | 역량 or 스킬 | 주요 키워드 | 긍부정 |
|---|---|---|---|---|
| 직원1님(EMP)은 개발업무(SKIL)에 있어 우수한 역량을 바탕으로 솔선수범 하는 모습을 보여주셨습니다. | 직원1 | 개발업무 | 우수한, 솔선수범 | 긍정 |
| 직원2님(EMP)은 원활한 인간관계(CAPA)를 바탕으로 동료들을 잘 다독여 주셨고, 그 결과 기한에 맞춰 작업을 완료할 수 있었습니다. | 직원2 | 인간관계 | 원활한 | 긍정 |
| 직원3님(EMP)은 새로운 디자인을 고안하는 작업(SKIL)에 있어 매우 창의적이고 독창적인 결과물을 만들어내십니다. | 직원3 | 디자인 고안 | 창의적, 독창적 | 긍정 |
| (윗문장에 이어) 하지만 보고서 작성(SKIL)등의 업무에 있어서는 꼼꼼함이 필요합니다. | 직원3 | 보고서 작성 | 꼼꼼함 | 부정 |
마치며
본 포스팅을 통해 자연어처리 연구에서 해결하고자 하는 다양한 과제들과, 해당 과제들이 현업 및 서비스에 어떻게 활용되고 있는지를 확인해 보았다. 위에서 언급한 바와 같이 자연어처리는 인간의 언어를 다루는 기술로 언어가 포함된 모든 영역에 확장이 가능하며, 본 팀의 업무 분야인 HR Analytics도 자연어처리가 필요한 분야중 하나이다. 어떤 영역에 있어 자연어처리 기술은 이미 현업에 깊숙히 녹아들어 있으며, 아직 적용되지 않은 부분들에 있어서도 향후 활용될 여지가 많아 기술의 수요가 매우 높다고 생각된다. 이러한 이유로 본 포스팅에서는 자연어처리 연구에서 주로 관심을 갖고 있는 문제들과 해당 문제를 학습하기 위한 데이터, 또 실제 적용사례를 정리해보았다.
참고자료
- 자연어처리 문제 정의 – https://www.ibm.com/blogs/watson/2020/11/nlp-vs-nlu-vs-nlg-the-differences-between-three-natural-language-processing-concepts/
- Predictive Analytics in Human Resources: Tutorial and 7 case studies – https://www.aihr.com/blog/predictive-analytics-human-resources/
- How Natural Language Processing can Revolutionize Human Resources – https://www.aihr.com/blog/natural-language-processing-revolutionize-human-resources/
- 텍스티오 – https://www.codingworldnews.com/news/articleView.html?idxno=4166
- BERT – https://arxiv.org/abs/1810.04805
- AI 적용 HR 서비스 요약 – https://towardsdatascience.com/5-companies-that-are-revolutionizing-recruiting-using-artificial-intelligence-9a70986c7a7e